
Robots.txt – это обычный текстовый файл в формате .txt. Этот файл содержит инструкции и директивы для поисковых роботов. Он может содержать директивы, запрещающие к индексации определённые файлы сайта, папки целиком и документы. Файл служит для ограничения доступа ботам поисковых систем к определённым частям сайта.
Robots.txt был принят стандартом — консорциумом W3C 30 января 1994 года, и с тех пор используется большинством известных поисковых машин. Следование стандарту добровольное.
Robots.txt содержание
(Что такое SEO можно прочитать в нашей статье)
Поисковые роботы при каждом сканировании сайта обращаются именно к Robots.txt для того, чтобы узнать, можно ли сканировать те или иные разделы вашего сайта, поэтому именно этот файл оказывает непосредственное влияние на SEO. На любом сайте может содержаться конфиденциальный контент либо служебный, сканирование которого никак не идёт на пользу SEO.
Например, на нашем сайте после заполнения форма отсылает на специальную страницу. Страница очень важна для работы сайта, но содержит очень маленькое количество информации, настолько небольшое, что поисковик вряд ли будет её правильно сканировать, и уже точно невозможно будет заполнить Description для этой страницы.
В Robots.txt также указывается путь к Sitemap. Если допустить ошибку в инструкциях и директивах, сайт может полностью пропасть из поискового индекса. Важно уметь корректно настраивать данный файл, так как от этого зависит видимость вашего сайта в поисковых системах и дальнейший рост объема трафика на проекте, именно поэтому и написана эта статья.
Первое, что изучает любой SEO-специалист – это правильность написания Robots.
Где находится и как создать Robots.txt
Файл robots.txt располагается в корневой директории сайта. На большинстве хостингов в папке public_html.
Проверить его наличие довольно просто. Надо перейти по ссылке:
https://вашсайт.ru/robots.txt, где “вашсайт” заменяется на доменное имя вашего сайта.

Ручное создание robots.txt
Для ручного создания файла достаточно воспользоваться любым текстовым редактором. Лучше всего:
- Блокнот;
- NotePad++
Не рекомендуется использовать для написания этого файла Microsoft Word, поскольку Word зачастую использует много служебных скрытых символов, которые могут быть перенесены в файл robots.txt и помешать его созданию.
После написания файла его загружают в корневой каталог сайта, чаще всего public_html. Проверить это тоже легко. Рядом с ним находятся файлы .htaccess и index.php.
Более подробно о файле .htacces, о его функционале и правильной настройке можно прочитать в нашей статье : Что такое .htacces.
Для загрузки используют:
- панель управления сервером (обратитесь к своим хостерам с вопросом, как это проще сделать);
- консоль, админку в CMSв WordPress – при помощи плагинов, например, Yoast;
- FTP-клиент, например, TotalCommander или FileZilla.
Не имеет значения, какой из способов вы выберете.
Создание robots.txt при помощи онлайн генератора
Лучше не пользоваться этим вариантом, либо подходить к процессу творчески. У каждого сайта свои правила создания этого файла. Отличаются они и для Яндекс и Google. В любом случае, лучше проверить, подходит автоматический вариант вашему сайту или нет. Например, CY-PR В WordPress для этого есть плагин ClearflyPro. Готовые шаблоны В сети существует масса готовых шаблонов robots.txt для популярных CMS WordPress, Joomla, Drupal и так далее, но в любом случае, они не решают конкретно ваших проблем, и всё равно их надо проверять и творчески относиться к написанию своего файла, который подходит для вашего сайта.
Как редактировать?
В процессе работы у вас может возникнуть необходимость в дальнейшем редактировании Robots.txt. Делается это прямо в самом файле. Не забывайте, что это простой текстовый файл. В различных CMS существует много плагинов для редактирования Robots.txt прямо из административной панели. Например, Yoast в WordPress
Директивы Robots.txt
В Robots.txt прописываются директивы для роботов поисковых систем, эти директивы помогают им понять, какие страницы или разделы индексировать, а какие – нет. Рассмотрим, какие директивы что означают.
User-agent — это обязательная директива. Она определяет, к какому роботу будут применяться прописанные ниже правила. Это обращение к конкретному роботу или всем поисковым ботам. Все файлы начинаются именно с этой строчки.
Disallow — запрещает индексирование разделов или отдельных страниц сайта. Чаще всего запрещают индексировать:
- страницы пагинации;
- страницы с личными данными пользователей;
- страницы с результатами поиска внутри ресурса;
- дублирующиеся страницы;
- логи;
- архивы дат и авторов, если там невозможно сгенерировать Descriptions;
- служебные/технические страницы.
В ней можно применять специальные символы * и $.
Sitemap — указывает путь к файлу Sitemap, который размещен на сайте. Эта директива очень важна, потому что сообщает ботам расположение XML карты сайта. Нужно указывать полный URL. Она важна для поисковых машин Google и Яндекс, так как при обходе сайта в первую очередь они обращаются именно к Sitemap, где показана структура ресурса с внутренними ссылками, приоритетами индексации страниц и датами их создания или изменения.
Несмотря на существование этой директивы, рекомендуется добавить адреса файлов Sitemap в Яндекс Webmaster и Google Search Console. Это ускорит их обработку.

Allow — разрешает индексирование разделов или отдельных страниц сайта. Это противоположная Disallow директива, она тоже допускает использование спецсимволов.
Clean-param — указывает роботу, что URL страницы содержит параметры (например, UTM-метки), которые не нужно учитывать при индексировании. Запрещает ботам обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц. В основном, проблема динамических параметров встречается на сайтах интернет-магазинов, а именно в URL-адресах для передачи данных по источникам сессий, персональных идентификаторов посетителей.
Crawl-delay — эта директива уже не поддерживается Яндексом и Google. Задает роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Рекомендуем вместо директивы использовать настройку скорости обхода в Яндекс.Вебмастере.
Чаще всего это необходимо для очень больших сайтов. Для небольших и средних сайтов вообще не имеет смысла использовать эти настройки.
Что нужно исключить из индекса
- В первую очередь, исключить из поиска нужно любые дубли страниц. Поисковикам явно не понравится, если к одному и тому же контенту будет доступ по разным адресам. Это точно запутает поисковик, и он не будет понимать, какая именно страница является canonical. У различных CMS дубли часто появляются в процессе создания страниц. Например: https://seo/?utm_source=fact должно быть https://seo/
Вопрос решается при помощи масок:
Disallow: /*?
Disallow: /?s=
- Все страницы с неуникальным контентом. Например, с цитатами с других сайтов.
- Все страницы с техническим контентом типа “Спасибо. Ваша заявка принята ”.
- Все файлы, относящиеся к CMS ( для WordPress).
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-json/
Disallow: /xmlrpc.php
Disallow: /readme.html
Кириллица в файле Robots.txt
Писать кириллические символы в директориях robots.txt, а также в HTTP–заголовках сервера запрещено.
Чтобы указывать названия кириллических доменов, воспользуйтесь Punycode. URL-адреса указывайте в кодировке, которая соответствует структуре ресурса.
#Неверно:
User-agent: Yandex
Disallow: /корзина
Sitemap: сайт.рф/sitemap.xml
#Верно:
User-agent: Yandex
Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%
D0%B8%D0%BD%D0%B0
Sitemap: http://xn--80aswg.xn--p1ai/sitemap.xml
Синтаксические правила
- Файл должен называться “robots.txt”.Никаких заглавных букв или кириллицы.
- На сайте может быть только один robots.txt. В отличие от .htaccess действия robots.txt распространяется всегда на весь сайт. Настроить его для отдельных разделов невозможно.
- Robots.txt необходимо размещать только в корневом каталоге сайта.
- Robots.txt. допускается размещать в субдоменах сайта, например: https://mysite.ru/robots.txt либо https://df-mysite.ru/robots.txt
- Любой текст, который следует после символа #, считается комментарием, это нужно для того, чтобы оставлять себе заметки, зачем нужна та или иная директива.
- Robots.txt может содержать группы. В любой группе допускается написание нескольких директив, каждая директива пишется с новой строки.
- Файл robots нужно создавать в формате текстового документа в кодировке UTF-8, включающей коды символов ASCII. Иные символы применять запрещено. По этой причине и не стоит использовать Microsoft Word.
- В группе содержится информация:для какого User-agent (поисковикам) прописываются директивы группы; к каким файлам или каталогам у агента есть доступ, а к каким – нет. User-agent: * — позволяет индексировать ваш сайт ВСЕМ поисковым роботам. Это очень удобно, поскольку есть много поисковиков, кроме Яндекс и Google.
- Инструкции в группах считываются сверху вниз.Поисковый бот будет следовать директивам лишь одной группы, агент пользователя которой соответствует ему больше остальных.
- По умолчанию robots разрешает индексировать все страницы либо каталоги: если они не запрещены директивой Disallow; если директива пустая; файл недоступен – выдает 404 ошибку или любой другой ответ на запрос робота, отличающийся от HTTP-кода со статусом 200 OK (проверить ответ сервера можно здесь); robots.txt отсутствует.
- Размер файла не должен превышает 500 КБ;
- Инструкции зависят от регистра. Например, директива Disallow: /file.asp влияет на URL-адрес https://www.myru/file.asp, но не применима к http://www.mysite.ru/File.asp.
- Пробел никак не влияет на инструкции в файле.Нет разницы, сколько пробелов вы проставите в robots.txt, но лучше, чтобы они использовались только в соответствующих местах, облегчая читабельность и ориентирование в файле.
- В директивах нет закрывающих символов. В конце каждого правила нет необходимости проставлять точку и прочие закрывающие символы.
- Названия правил указываются с заглавной буквы на латинице. Корректное написание – “Allow”, а не “ALLOW”.
- Пустой перенос строки применяется только для User-agent. В конце данной директивы пустой перенос строки считается окончанием инструкций по определенному User-agent. Написание нового User-agent без переноса строки может не учитываться.
- Символ “/” применяется для статических страниц. К примеру, Disallow: /wp-includes запрещает индексировать одну из папок ядра WordPress.
- Порядок следования директив. Роботам поисковых систем не важна последовательность директив. Если директивы Allow и Disallow конфликтуют и противоречат друг другу, приоритетной будет Allow.
- Не нужно прописывать в robots инструкции для каждой отдельной страницы. Так делать можно, но в исключительных случаях. Например, для указания пути к файлу sitemap: Sitemap: https://mysite.ru/sitemap_index.xml
- В целом же, старайтесь указывать общие директивы, применимые для всех типовых URL-адресов вашего веб-ресурса. Эффективный robots.txt – это краткий в объеме и одновременно обширный по смыслу файл.
Как проверить Robots.txt?
После загрузки файла на сервер его нужно обязательно проверить на доступность и на ошибки.
Проверка на сайте
Если вы сделали все верно и загрузили файл в корневой каталог сайта, он станет доступным по ссылке типа https://mysite.ru/robots.txt (вместо mysite.ru указывается URL вашего ресурса).
Это общедоступный файл и его можно посмотреть и изучить у любого сайта.
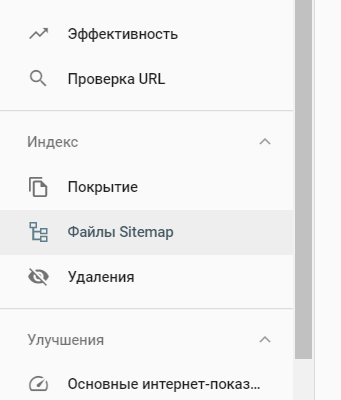
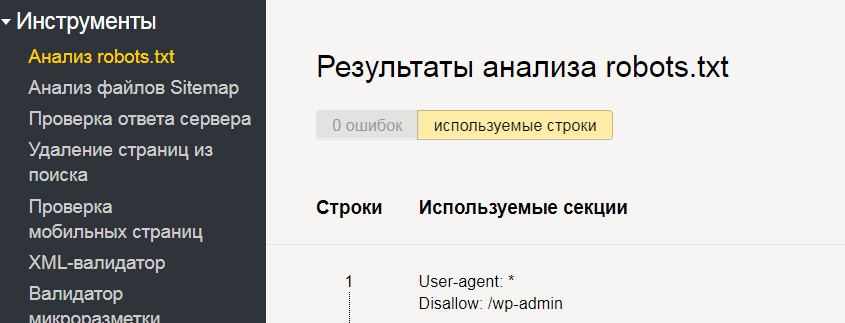
Проверка на ошибки
Сделать это можно двумя способами:
Видео по теме Robots.txt
Заключение
Файл Robots.txt – это один из ключевых инструментов для успешного SEO-продвижения сайта. С его помощью вы можете непосредственно влиять на включение в индекс различных страниц и разделов веб-ресурса.
